We are testing Clustering using hazelcast 2.5.0 and openfire 4.5.1, and especially fail-over behaviour.
Currently isn’t successful. We have 2 node cluster setup with OF 4.5.1 What happens is that after shutting down one of the nodes (the junior), Muc behaviour is not restored. The client is reconnecting, Private chat is possible, but the client cannot rejoin the room. Further investigation showed that no subdomains (conference, search, etc ) were available anymore. a Disco#items on the server returns zero items.
We see in the logs lots of errors where the server tries to resolve the conference domain as a remote connection.
When the second node is restored, all is working again.
The issue is definitely Cache related. So i focused on the cache behaviour:
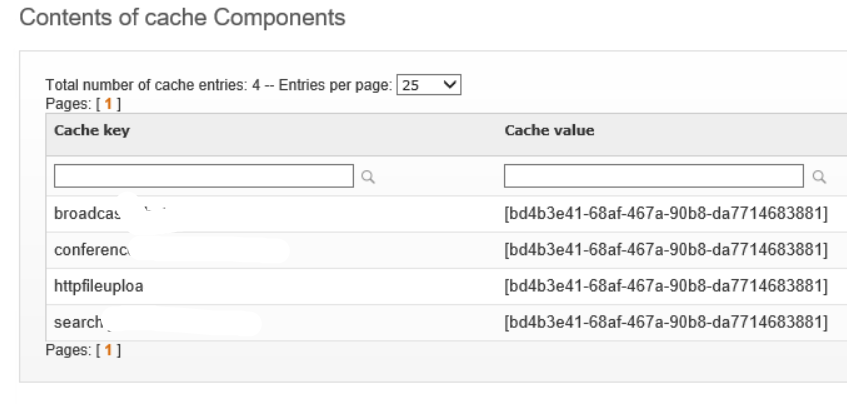
initially a server has a “Disco Server Items” cache with 4 items in my case:
[broadcast.jchat.oftst]
[conference.jchat.oftst]
httpfileupload.jchat.oftst]
[search.jchat.oftst]
Each referring to the Node id of the same clusternode. Somehow I would expect 8 entries, four for each Clusternode.
When I stop the other clusternode, with the client connected to this remote, nothing changes. The Client is reconnecting to the other node. cache is not changed.
When I restart the node again, after the node rejoining the cluster, I see the cache content is changed. All components now point to the restarted node. so components are hosted on the restarted node.
When I again stop the same clusternode, Component cache is empty and client is not functioning, because of missing components.
So my questions are:
-
Should there not be a cache entry for each component on each node (8 instead of 4)?
-
Why are the Cache entries replaced when a new node enters the cluster?