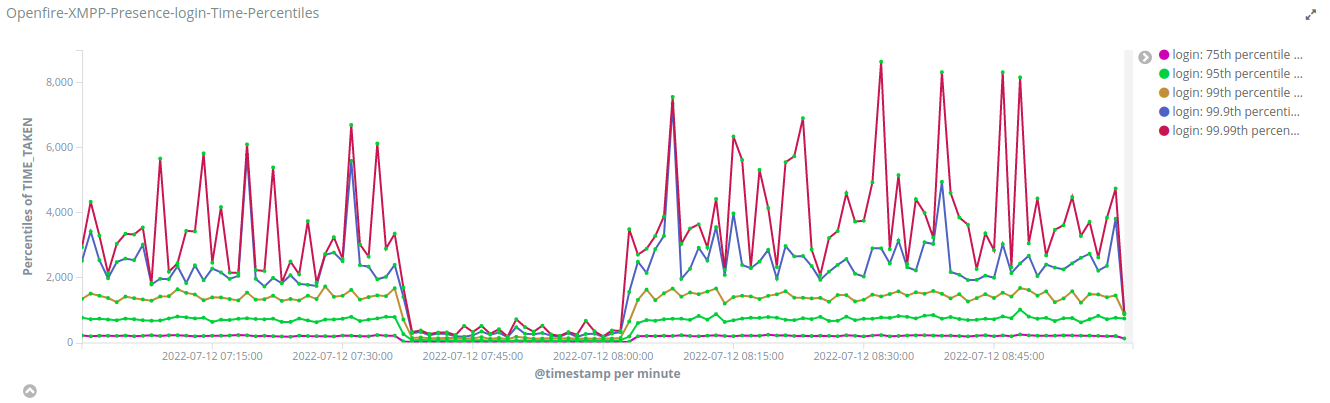
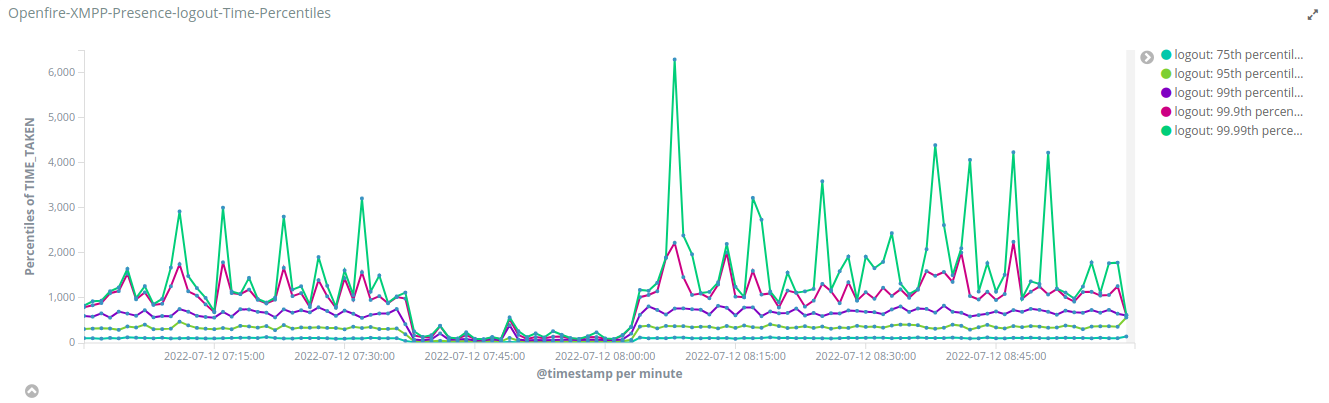
We are using Openfire version 4.4.4 in production in clustering mode using openfire-hazelcast-plugin version 2.4.2. We have around 12k-15k concurrent sessions during peak time.
We have implemented a mechanism to compute the time taken by the Openfire application to process packets. We saw a massive difference in the processing time of presence (available/unavailable) packets in stand-alone/single-node-cluster and two-nodes-cluster.
We have verified thread dumps and there is no issue at that end. Eventually, we are unable to figure out what’s causing these delays. Any help/suggestion in this regard will be highly appreciable. Thanks a lot in advance.
Hello Guus, we haven’t cached rosters yet. Our cache size is really really small, 20-30 Mb only. If roster size was an issue, it should be problematic in standalone mode (or single node cluster) also.
Not necessarily. When processing presence stanzas, the subscription state (which is captured in the roster) is needed. When a local cluster node doesn’t have the roster in cache, it might need to obtain it from another node.
You could try experimenting with configuring that cache to retain backup copies on all nodes. Hazelcast has some options for that. I’m not sure if this benefits parallel processing, or if it’s more a matter of disaster recovery - but it’s worth a try.
As I have mentioned earlier, we have disabled the roster cache. So for every presence stanza hit, we get rosters from the database only. So, standalone mode and clustered mode should be the same in terms of rosters fetching.
We have debugged the slowness further and have the following analysis for the time taken to get a key from User Routing Sessions cache
If key is present
Time taken on both members = t
If key is absent
a. Time taken on senior member = t
b. Time taken on junior member = 10 * t
This means reading a non-existent key is slow on junior members. We are using Openfire version 4.4.4 with openfire-hazelcast-plugin version 2.4.2. And we have used default map configs as provided in this plugin.
Any inputs over this slowness issue will be highly appreciable. Also, I’m unable to figure out whether map-store is being enabled or not. If it is enabled, then what can be the possible consequences of disabling it, or would it help us in solving this issue?
Is there any way you can do an analysis with current releases of Openfire and hazelcast plugin? Openfire has gotten a lot of clustering love since that release and a current release may have this issue resolved.
@akrherz thanks for your suggestion. We have built certain custom business logic over Openfire, and it would surely not be a straightforward task to test it with current releases. Any leads to resolve this issue with release versions currently used by us will be highly appreciable.