What you’re saying is that currently, the session is indirectly it’s own backup deliverer? That would correspond with my earlier thought that everything appears to be one session.
I am still worried by these log statements:
Unable to deliver a stanza (it is being queued instead), although there are available connections! RID / Connection processing is out of sync!
I can’t shake the feeling that something is off with the client implementation and/or load balancing setup.
A client can use more than one connection (HTTP request) at the same time to exchange data with the server. While it has send one HTTP request (to which no response has yet been returned), another HTTP request can be made to send more data.
The warning that is logged indicates that Openfire cannot identify the correct request to use to send back data. An obvious reason would be that the connections are all closed, but this specific warning is logged when there are open connections (but they do not have the expected ‘rid’ value).
class org.jivesoftware.openfire.websocket.WebSocketConnection // 108
public PacketDeliverer getPacketDeliverer() {
if (backupDeliverer == null) {
backupDeliverer = new OfflinePacketDeliverer();
}
return backupDeliverer;
} class org.jivesoftware.openfire.SessionManager // 386
public HttpSession createClientHttpSession(...) throws UnauthorizedException {
if (serverName == null) {
throw new UnauthorizedException("Server not initialized");
}
PacketDeliverer backupDeliverer = server.getPacketDeliverer(); // Returns the PacketDeliverer registered with this server.
// The PacketDeliverer was registered with the server as a module while starting up the server.
HttpSession session = new HttpSession(backupDeliverer, serverName, address, id, rid, connection, language);
Looking at the code every session is indeed it’s own backup deliverer. For websocket connections the proper deliverer (OfflinePacketDeliverer) is used while SessionManager uses the default deliverer as its backup deliverer. It may be a simple change to replace “server.getPacketDeliverer();” with “new OfflinePacketDeliverer();”.
Well, problems are not resolved. Maybe openfire is not optimized for http-bind for such amount of online users. Opened files by openfire increasing hour ny hour. It seems like connections not closes.
We try to use another solution for jabber-server.
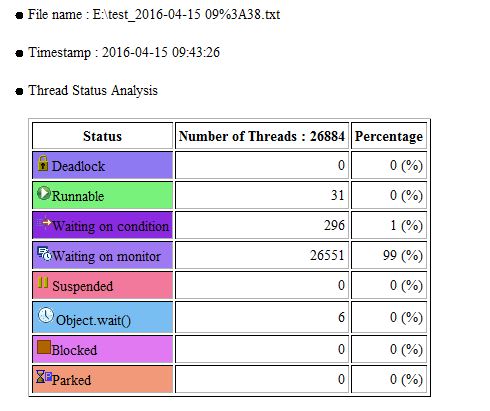
this is new stack with blocked 26551 threads by 1. this is one of the problem. Also we got another problem with opened files. We take them with lsof Number of “can’t identify protocol” is increasing. I think they are not properly closed connections. The log attached lsof-log.txt.zip (113925 Bytes) 2016-04-15_09_38.zip (694012 Bytes)
That what makes me wonder if we’re on the right track, LG. Loads of people have used BOSH in that time. If there was such a bug, we would have noticed by now.
[OF-813] Memory leak - IgniteRealtime JIRA and there are a few threads here where a httpbind memory leak was suspected but it couldn’t be found. Some fixes were applied without knowing whether they fixed the root cause. It seems that it is not always triggered. And with little dropped connections this bug will be hard to notice.
It seems that here one connection is dropped before it receives its packages. And/or it has an issue receiving packets and can only send data. Fixing the client would be a great idea but the server should keep running w/ issues.
Nevertheless assigning here the standard deliverer instead of the backup one seems to be a bug. As there are no comments in the code which explain why the std. del. was used I can only assume that Gato or Derek or whoever implemented this in 2006 used it as a quick solution for initial tests w/ adding a “/* TODO replace w bck. del. */” note.
Now that you mention HAProxy - there were similar issues with Netty + NIO --> Handling TCP RST · Issue #3193 · netty/netty · GitHub
Maybe Openfire has similar issues and keeps the send connetion open after receiving a RST by HAProxy.
@Guus This would explain why we don’t see this issue quite often as normal clients use the FIN handshake to close the session. So one should fix both issues (proper RST handling and proper backup deliverer) if it’s possible to recreate it. Anyhow my knowledge about Mina/NIO is small and creating a testcase for the potential RST issue may be hard.
Can you share the haproxy configuration you used before and the exact haproxy version so we can create an issue with steps how to hopefully reproduce this issue?
We have nginx and haproxy in front of openfire. because chat is additional module for portal. Nginx standing infront - runs for SSL termination. For proxing chat requests config on nginx
After upgrading from Openfire 3.9.3 to 4.0.2 we’re seeing what seems to be the same issue. These exceptions keep appearing in the log (still unclear what the cause of these are):
2016.09.26 14:16:28 WARN [Jetty-QTP-BOSH-100612]: org.eclipse.jetty.server.HttpChannel - /http-bind/
java.lang.IllegalStateException: state=EOF
at org.eclipse.jetty.server.HttpInput.setReadListener(HttpInput.java:376)
at org.jivesoftware.openfire.http.HttpBindServlet.doPost(HttpBindServlet.java:152)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:707)
at org.jivesoftware.openfire.http.HttpBindServlet.service(HttpBindServlet.java:116)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:790)
With every exception the number of abandoned file descriptors increases by one.
Looking at the HttpBindServlet.doPost method there’s this:
final AsyncContext context = request.startAsync();
// Asynchronously reads the POSTed input, then triggers #processContent.
request.getInputStream().setReadListener(new ReadListenerImpl(context));
If an exception is thrown in setReadListener (as is the case in the stack trace), then context.complete() is not invoked. Should there be a try-catch here to make sure complete is called on the context object if an exception is thrown?