I’m sorry if thread like this already exists, but i’ve not found any that helped to resolve issue.
Server config (same for 4.3.2 and 3.7.0).
CPU: 4 cores
RAM: 8GB
Used software:
OS: CentOS 7.5
SELinux: Enforcing
Kernel: 3.10.0-957.10.1.el7
Openfire: 4.3.2 (Installed with RPM, LDAP auth)
JRE: 1.8.0_202-b08 (Bundled with Openfire)
MariaDB (INNODB): 5.5.60-1.el7.5
So, we tried to migrate to Openfire 4.3.2 from Openfire 3.7.0 and got issues with performance.
On Openfire 4.3.2 server we used same configuration for cache as on 3.7.0:
cache.userGroup.size: -1
cache.username2roster.size: -1
cache.vcardCache.size: -1
cache.group.size: -1
cache.userCache.size: -1
cache.lastActivity.size: -1
cache.offlinePresence.size: -1
cache.userGroup.size: -1
cache.groupMeta.size: -1
cache.listsCache.size: -1
We used same LDAP server for auth for 4.3.2, like on 3.7.0.
So our problem is clients login on Openfire 4.3.2 is much slower than on 3.7.0. For 2 hours on 4.3.2 we had online 150 users of 1000. On 3.7.0 we had 1000 users online in 30 minutes.
On 4.3.2 CPU load was too low than we expected, 10-30% 1 core load by openfire, mysql had no load and no slow queries as well. On 3.7.0 with initial clients logging in CPU load was 100% 1 core by openfire, 50% mysql with some slow queries, after all users logged in cpu usage is low.
On 3.7.0 mysql with MyISAM, on 4.3.2 with INNODB. Both DB servers using some tuning to use more ram. Java ram limit is 2GB (-Xms256M -Xmx2048M). Avail ram 3-4GB.
What can we try or maybe someone can point to similar threads?
Performance issue is that on older version of openfire and higher load users are logging in much faster, than on newer version and new server load is, as you noticed, almost idle and client logins are very slow.
We want to find what’s the problem with new server.
Yes, most of clients (80-90%) are trying to log in immediately after openfire is started.
On server was errors from some clients about SSLv3 unavailable, after we enabled SSLv3 and restarted openfire these errors gone. Also that server could not get some groups from ldap and assign roster to some deleted users in shared groups.
On clients was one error - changed SSL certificate and client need to confirm trust.
These errors was on old server aswell.
LDAP server is 1 CPU, 1GB RAM with 20% load when all users try to login and idle after login. Network between Openfire and LDAP server is 1gbit connected to the same switch.
If this is Openfire, then it is probably waiting for something (some kind of timeout, perhaps). Try to create one or two java thread dumps from the Openfire process (while clients are connecting). That might give us a clue what’s going on.
Hi.
Can’t create dumps today, sorry. We’ll try to do it as fast as possible.
A little update on our environment. We have 1050 users and 102 shared roster groups (each shared with all users).
In Openfire 4.3.2 we’re using ldap pooled connections, but not ldap paged results, 3.7.0 does not have such options applied. Our LDAP server can give 2000 results in one request. Would using ldap paged results affect with our config?
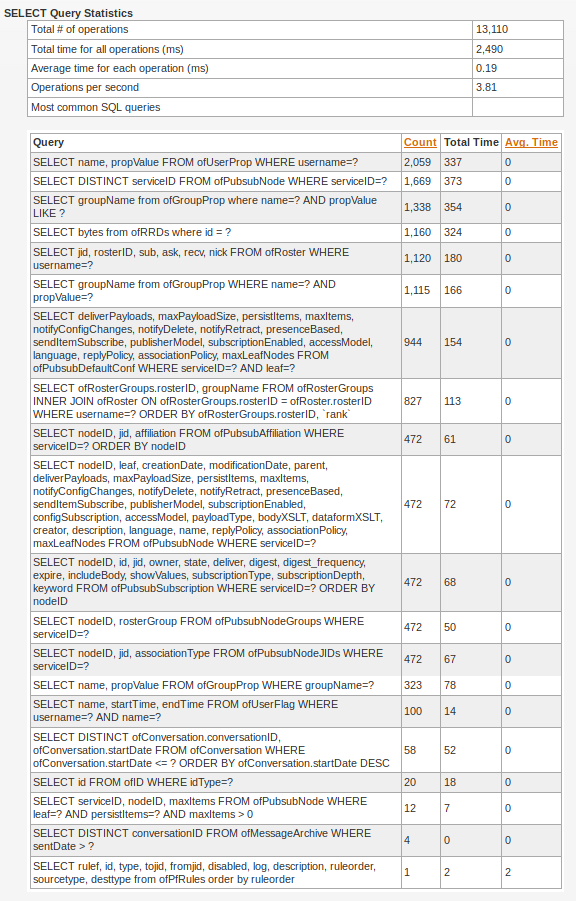
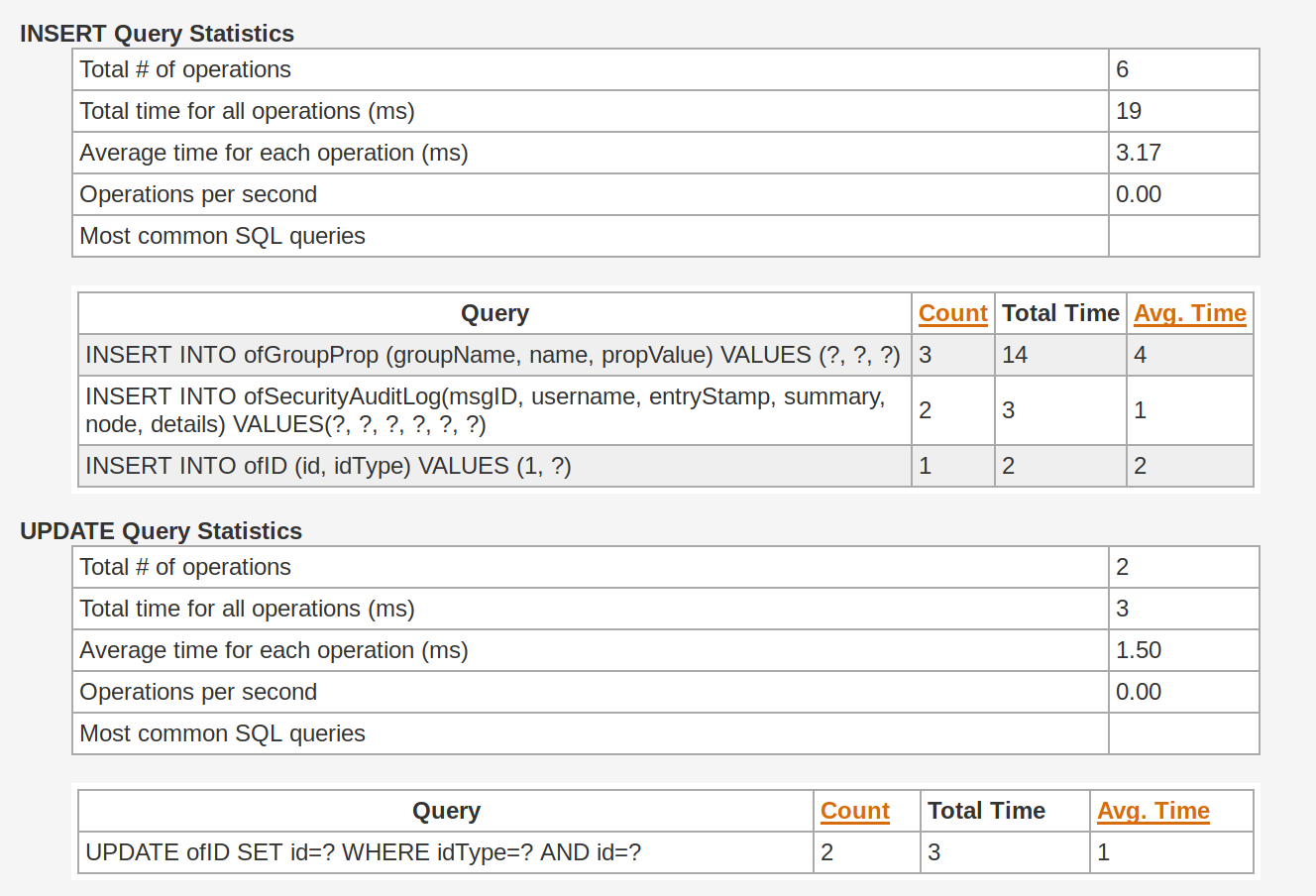
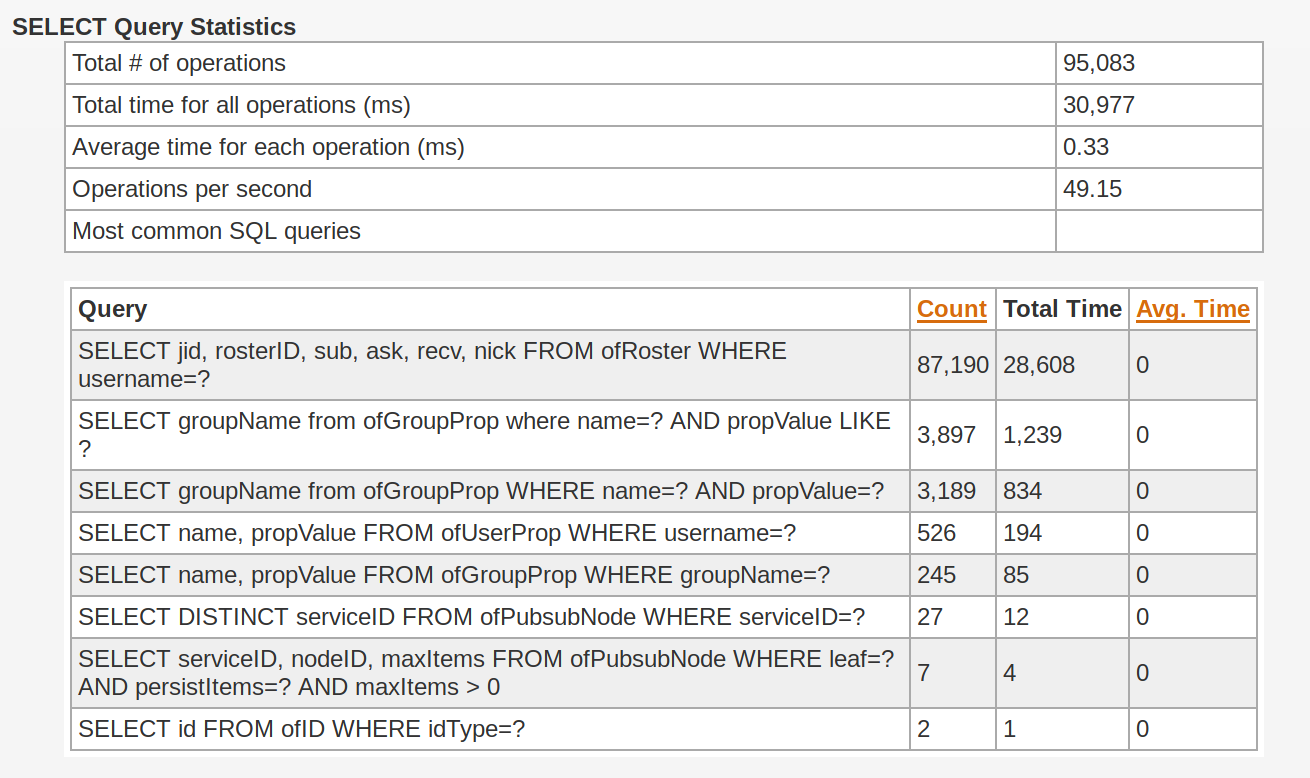
Also on 4.3.2 in database query statistics when sharing roster group with all openfire executes 35-40k sql queries to share one group, so sharing is also very slow 10-15 minutes. On 3.7.0 database query statistics does not work. Sharing almost everytime depends on group size and small group can be shared in 30 sec and large group in 5-7 min. On 4.3.2 any group sharing takes same amount of time. Do we have too much groups and should use less? Or it could be related to Openfire waiting something?
So i’ve run new server alongside with current old server. For now without active users at all.
On the new server i tried to share roster group that previously wasn’t shared and it took 10 minutes, while i waited response from openfire i looked at load on openfire and ldap server.
On openfire cpu load was 20-30% and on ldap cpu load was 60% while sharing group, after sharing process finished load on both servers almost idle.
Then i tried to disable ldap.connectionPoolEnabled on new server and tried to share another group that wasn’t shared ever before and this took 30 seconds like on the current old server, load on new server was 1 core 100% by java (like on current old server), and 60% on ldap server.
On current old server no such option ldap.connectionPoolEnabled is set in system properties so it should be off.
I’ve found so many recommendations to enable ldap.connectionPoolEnabled and it seems that it is not so simple.
Maybe it works fast without users online? Maybe i should not use ldap.connectionPoolEnabled? Has anyone experienced same issues?
yes…you should be using connection pool. on your ldap are you using ldaps or regular ldap? Also, please set ldap.pagedResultsSize =1000 to see if that helps.
I don’t have as many as you! Its likely not an ldap issue, as it is a database issue. IIRC, shared groups are pulled from ldap, but then stored in the database. perhaps thats the bottle neck. Maybe @guus or @gdt could offer some insight there, as I know very letting about DBs.
These amounts of groups is somewhat atypical. We’ll probably need to reproduce / debug a setup like the one you’re using, but that goes beyond what I can do in my spare time.
Having thread dumps would be a start for that - as it might give us a clue what’s causing things to slow down.
This seems waaaay to much. What queries are these?
Can you create a dump of the SQL queries that are being executed?
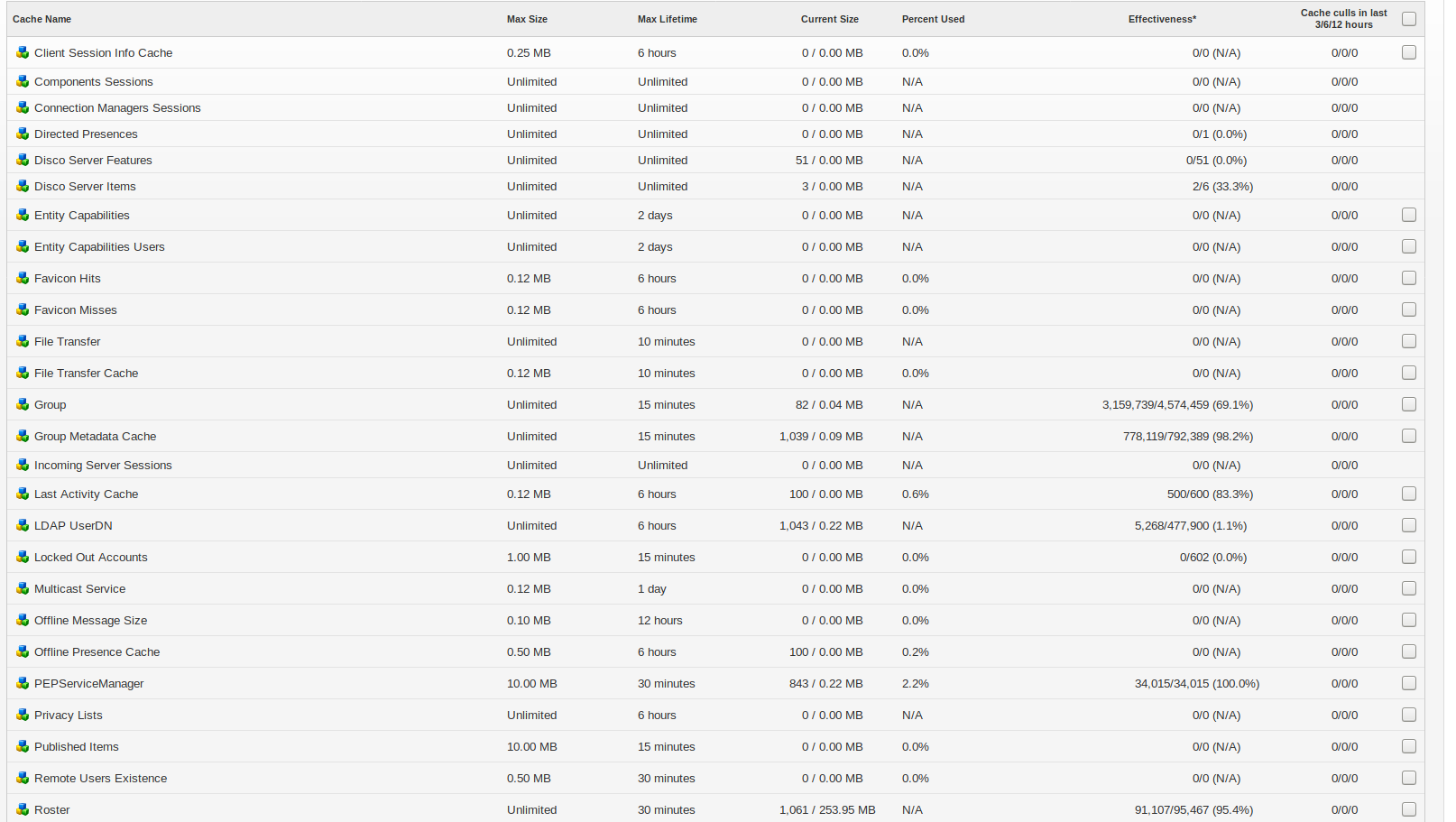
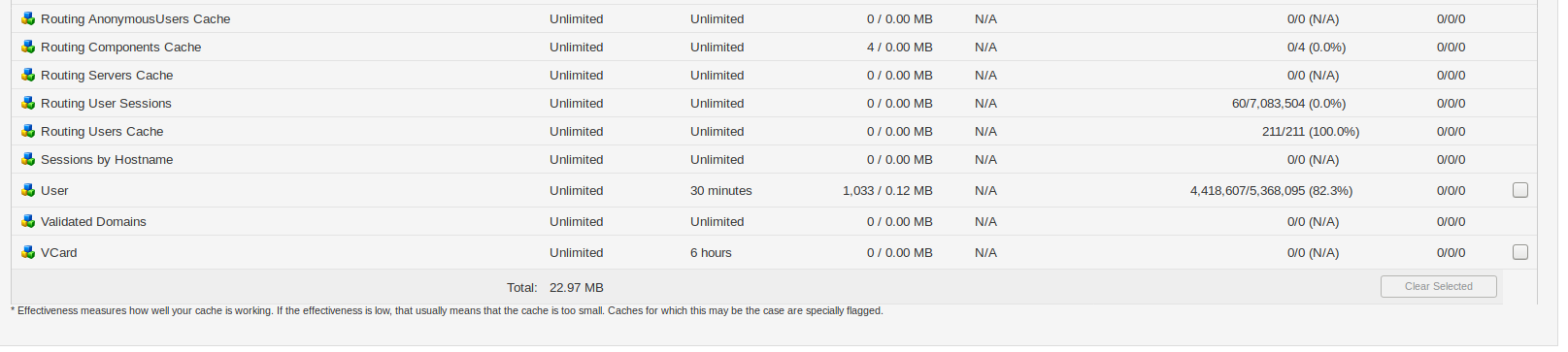
Also, please review your caches (via the Admin Console, Server > Server Manager > Cache Summary). Are there any caches that are full (or nearly full), have lots of usage but little effectiveness?
From your thread, I think this is suspicious. Maybe Openfire is suffering from a lot of lock contention while retrieving users that are on each-others roster.
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:502)
at com.sun.jndi.ldap.Connection.readReply(Connection.java:493)
- locked <0x00000000ee36f550> (a com.sun.jndi.ldap.LdapRequest)
at com.sun.jndi.ldap.LdapClient.getSearchReply(LdapClient.java:632)
at com.sun.jndi.ldap.LdapClient.search(LdapClient.java:555)
at com.sun.jndi.ldap.LdapCtx.doSearch(LdapCtx.java:1985)
at com.sun.jndi.ldap.LdapCtx.searchAux(LdapCtx.java:1844)
at com.sun.jndi.ldap.LdapCtx.c_search(LdapCtx.java:1769)
at com.sun.jndi.ldap.LdapCtx.c_search(LdapCtx.java:1786)
at com.sun.jndi.toolkit.ctx.ComponentDirContext.p_search(ComponentDirContext.java:418)
at com.sun.jndi.toolkit.ctx.PartialCompositeDirContext.search(PartialCompositeDirContext.java:396)
at com.sun.jndi.toolkit.ctx.PartialCompositeDirContext.search(PartialCompositeDirContext.java:378)
at javax.naming.directory.InitialDirContext.search(InitialDirContext.java:286)
at org.jivesoftware.openfire.ldap.LdapManager.findUserDN(LdapManager.java:1026)
at org.jivesoftware.openfire.ldap.LdapManager.findUserDN(LdapManager.java:949)
at org.jivesoftware.openfire.ldap.LdapUserProvider.loadUser(LdapUserProvider.java:104)
at org.jivesoftware.openfire.user.UserManager.getUser(UserManager.java:273)
- locked <0x00000000eb707918> (a java.lang.String)
at org.jivesoftware.openfire.user.UserNameManager.getUserName(UserNameManager.java:102)
at org.jivesoftware.openfire.user.UserNameManager.getUserName(UserNameManager.java:83)
at org.jivesoftware.openfire.roster.Roster.<init>(Roster.java:163)
at org.jivesoftware.openfire.roster.RosterManager.getRoster(RosterManager.java:127)
- locked <0x00000000ee34a050> (a java.lang.String)
at org.jivesoftware.openfire.roster.RosterManager.groupUserAdded(RosterManager.java:674)
at org.jivesoftware.openfire.roster.RosterManager.groupUserAdded(RosterManager.java:640)
at org.jivesoftware.openfire.roster.RosterManager.groupModified(RosterManager.java:323)
at org.jivesoftware.openfire.event.GroupEventDispatcher.dispatchEvent(GroupEventDispatcher.java:145)
at org.jivesoftware.openfire.group.DefaultGroupPropertyMap.insertProperty(DefaultGroupPropertyMap.java:483)
- locked <0x00000000c3a2ab20> (a org.jivesoftware.openfire.group.DefaultGroupPropertyMap)
at org.jivesoftware.openfire.group.DefaultGroupPropertyMap.put(DefaultGroupPropertyMap.java:78)
at org.jivesoftware.openfire.group.DefaultGroupPropertyMap.put(DefaultGroupPropertyMap.java:89)
at org.jivesoftware.openfire.admin.group_002dedit_jsp._jspService(group_002dedit_jsp.java:341)
On 3.7 we don’t have ldap userdn cache enabled, so no cache stats. And it seems on 3.7 there is no ldap userdn cache, on fresh 4.3.2 installation this cache is in cache summary even if it does not in system properties.
I’ve tried 4.3.2 with mysql 8 instead of mariadb 5.5 - no changes.
I’ll try 4.2.3 version, found some threads mentioning problems on 4.3.2, but not on 4.2.3. And i’ll try nightly build aswell.
I’ve tried to share one group on openfire 4.2.3 fresh installation with mariadb 5.5.
Took thread dump at 10k sql queries, after that can’t get any thread dumps, aren’t creating. Took 20-25 minutes to share one group on server with no online users and no shared groups.
Within this one group are 21 members. Sharing wth all 1000 users. Other users are in separate groups. From 5 to 100 members in each group. 100 groups total.