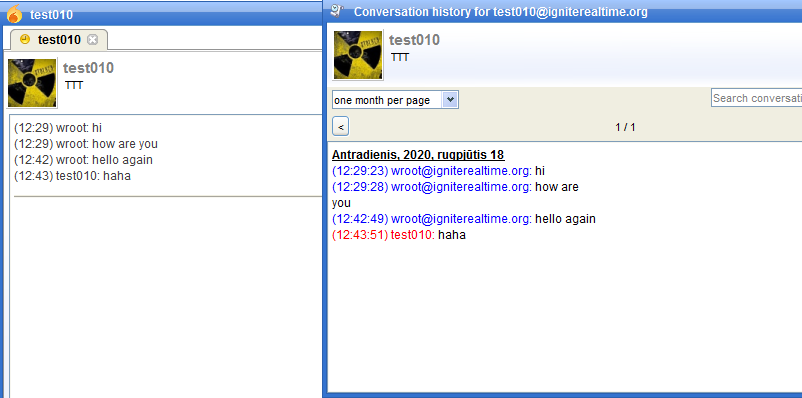
An issue in the chat history of the new Spark 2.9.0.
If I’m John Red (username in AD = j.red@domain.com) and I open the chat history with Mary Green (username in AD = m.green@domain.com), I see all the messages of Mary Green with the right name Mary Green, while I see all my messages with j.red@domain.com.
So for example:
(08:30) j.red@domain.com: Hello. How are you?
(08:31) Mary Green: Fine well. Please send me your new release.
(08:32) j.red@domain.com: OK. Will do.
No problem with Spark 2.8.3 (I see John Red in all the lines).
In Spark 2.8.3:
(08:30) John Red: Hello. How are you?
(08:31) Mary Green: Fine well. Please send me your new release.
(08:32) John Red: OK. Will do.
In Spark 2.9.0:
(08:30) j.red@domain.com: Hello. How are you?
(08:31) Mary Green: Fine well. Please send me your new release.
(08:32) j.red@domain.com: OK. Will do.
There is also another way of showing history. If you right click in a chat window and select View Log, it will present a different view of history, which also is using JID+resource. It was using same display method in 2.8.3 also. Maybe we should remove this duplicating option to view history altogether.
I’ve now also fixed the nickname in the other window. As for the third option: if it doesn’t hurt, let’s keep it? It displays raw/unparsed data from the log files, I think, which could have benefits to keep, if only to have an unambiguous view of the history. The nicknames that we display in other places is the current nickname, not the nickname that was used when the message was sent, which might be confusing. Having a log that simply contains the JIDs might be a good way to know exactly who said what.